Objective
Common quality of today's information technology, in an aim to become able to identify items, is to mark up every single item. – The Model of Meaning heads to build the foundation to manage-without any such markup.
The approach is about content representation in the literal sense of the term.
Updates: none so far
Monday, August 20, 2007
Friday, August 10, 2007
Search results on graph algorithms
I asked before, whether or not someone might be interested in improving the kind N network detection algorithm. -- Well, I figured, I "shot first, asked then", figuratively, implemented the approach before asking Google about the issue. Hm. Foolish.
But, as I grasped the idea now, that's a chance for further improvement of the detection approach. However, I want to get that baby implemented once in complete before I go into any source improving. Hence, I keep the offer: If you're interested in diving into MOM, the source, want to improve it, its source, or especially the kind N network detection, please let me know. I'd be curiously to hear from you.
Updates: none so far
But, as I grasped the idea now, that's a chance for further improvement of the detection approach. However, I want to get that baby implemented once in complete before I go into any source improving. Hence, I keep the offer: If you're interested in diving into MOM, the source, want to improve it, its source, or especially the kind N network detection, please let me know. I'd be curiously to hear from you.
Updates: none so far
Detecting kind N networks: Speed comparison of matrix and graph based approaches
The approach of determining kind N networks I took a year before -- when I was still using Perl and drafting the approach by functional programming [which later became hardly to comprehend] -- was to mark all the edges into a matrix and detect rectangular, non-intersecting, virtual areas there.
Virtual areas in a matrix? If you consider a non-zero cell of a matrix to be a spot of an area, a larger such area constitutes by adjacent spots (non-zero cells). I consider them being rectangular when they cover an area of at least 2 x 2 cells of the matrix, better: at least 2 x 3 or 3 x 2. A 2 x 3 area equals the W network (3 x 2 is the M network; W and M networks both are kind N networks). Fine, so far. But virtual?
There might be lines of adjacent spots within the matrix, but the lines might be away from another line of spots, i.e. not adjacently. But some rows or columns away. These lines, together, although being disjacent, can get considered to constitute an area -- a virtual. That's because the x and y values represent a node each, hence the non-zero cells within the matrix are edges. There's really no need that the node which was set up to be column x to be fixed at that position. Hence, the columns -- and rows -- of the matrix are freely swappable. In other words, we shift around the marked spots within the matrix to get a real area.
See the picture aside: There are blue, red and green marked cells. Obviously, the blue spots form an area, since they neighbour each other.
The lower part of the green area is a step more complicated: We could get the 2 x 3 area, if we'd ignored the upper part of the green, by simply swapping columns 4 and 1. To get the remainder of the green, we need to swap rows 2 and 5. Which, of course would disrupt the blue area.
However, we could note down the blue area first and swap for the green area afterwards,
The red area, then, is the most complex one, at first glance, but after swapping around a bit, it gets found as well -- yet rather simply.
As the non-zero cells within the matrix are edges, a 10 x 10 matrix as a whole could contain up to a hundred different edges, i.e. get and be densely filled.
But there's a restriction with the matrix, not visible in the diagram: The columns and the rows represent the same nodes. So, as the MOM graph allows no loops, less than half of the matrix may be filled, actually, -- the upper right half of the matrix less the diagonal from top left to bottom right. So, in reality, the matrix never gets really dense.
However, I implemented the approach -- and while it worked fine with a matrix as small as 10 x 10 or 20 x 20, when I launched examination of a 1000 x 1000 matrix I quickly became aware, that approach might be "a bit" slow: It took hours on a 2 GHz machine (single core x86 CPU). Actually, the necessary processing time increased exponentially. -- And a thousand nodes is really not that much. Really, not even worth to mention: Just think about the number of words being part of a common day's news feed.
Well, now I developed another approach of detecting kind N networks within a MOM network, doing it by considering the edges only. That, effectively, leaves out the white spaces of the matrix.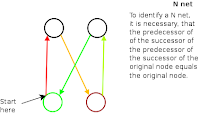
As before, I started with a relatively small net -- a hundred nodes and about 200 .. 250 edges. Which did it in less than half a minute, on a 400 MHz machine (single core CPU). Launching a 1000 nodes large test net with 2,500 to 5,000 edges, I learned it took about an hour. -- I became a bit scared because of that development, but then figured the reason for that slowness might be that it's just a 400 MHz machine only.
I put it onto the before mentioned 2000 MHz computer. -- The about 5000 edges got examined in less but three minutes. -- Phew!.
But I think, there are chances to speed up the approach, still. Anyone interested in improving the code or algorithm?
But, yes, sadly, I didn't check in the code yet, since I am after implementing detecting and replacing [the found] kind N networks. And the latter part I didn't figure out yet.
Updates: none so far
Virtual areas in a matrix? If you consider a non-zero cell of a matrix to be a spot of an area, a larger such area constitutes by adjacent spots (non-zero cells). I consider them being rectangular when they cover an area of at least 2 x 2 cells of the matrix, better: at least 2 x 3 or 3 x 2. A 2 x 3 area equals the W network (3 x 2 is the M network; W and M networks both are kind N networks). Fine, so far. But virtual?
There might be lines of adjacent spots within the matrix, but the lines might be away from another line of spots, i.e. not adjacently. But some rows or columns away. These lines, together, although being disjacent, can get considered to constitute an area -- a virtual. That's because the x and y values represent a node each, hence the non-zero cells within the matrix are edges. There's really no need that the node which was set up to be column x to be fixed at that position. Hence, the columns -- and rows -- of the matrix are freely swappable. In other words, we shift around the marked spots within the matrix to get a real area.

See the picture aside: There are blue, red and green marked cells. Obviously, the blue spots form an area, since they neighbour each other.
The lower part of the green area is a step more complicated: We could get the 2 x 3 area, if we'd ignored the upper part of the green, by simply swapping columns 4 and 1. To get the remainder of the green, we need to swap rows 2 and 5. Which, of course would disrupt the blue area.
However, we could note down the blue area first and swap for the green area afterwards,
The red area, then, is the most complex one, at first glance, but after swapping around a bit, it gets found as well -- yet rather simply.
As the non-zero cells within the matrix are edges, a 10 x 10 matrix as a whole could contain up to a hundred different edges, i.e. get and be densely filled.
But there's a restriction with the matrix, not visible in the diagram: The columns and the rows represent the same nodes. So, as the MOM graph allows no loops, less than half of the matrix may be filled, actually, -- the upper right half of the matrix less the diagonal from top left to bottom right. So, in reality, the matrix never gets really dense.
However, I implemented the approach -- and while it worked fine with a matrix as small as 10 x 10 or 20 x 20, when I launched examination of a 1000 x 1000 matrix I quickly became aware, that approach might be "a bit" slow: It took hours on a 2 GHz machine (single core x86 CPU). Actually, the necessary processing time increased exponentially. -- And a thousand nodes is really not that much. Really, not even worth to mention: Just think about the number of words being part of a common day's news feed.
Well, now I developed another approach of detecting kind N networks within a MOM network, doing it by considering the edges only. That, effectively, leaves out the white spaces of the matrix.

As before, I started with a relatively small net -- a hundred nodes and about 200 .. 250 edges. Which did it in less than half a minute, on a 400 MHz machine (single core CPU). Launching a 1000 nodes large test net with 2,500 to 5,000 edges, I learned it took about an hour. -- I became a bit scared because of that development, but then figured the reason for that slowness might be that it's just a 400 MHz machine only.
I put it onto the before mentioned 2000 MHz computer. -- The about 5000 edges got examined in less but three minutes. -- Phew!.
But I think, there are chances to speed up the approach, still. Anyone interested in improving the code or algorithm?
But, yes, sadly, I didn't check in the code yet, since I am after implementing detecting and replacing [the found] kind N networks. And the latter part I didn't figure out yet.
Updates: none so far
Thursday, August 09, 2007
How does a question get stored? Does an answer replace a question? How do we find out that there's a chance to get a question answered?
One day amidst my course of studies, I wondered about how questions (i.e. question texts) and answers might get stored in mind. That curiousity was the first step to the later Model of Meaning, nowadays also known as Content Representation model. I wondered whether an answer might replace a question one day:
To mention context together with a question applies meaning to the question. When the question gets answered, the anwer might accompany that meaning. -- Well, wenn the question is answered thoroughly, I think, the answer might replace the question.
Does that mean, that in mind the question gets stored as a placeholder for any upcoming answer? How long does any such placeholder [if it is such a one] hold that place before it gets replace [if it gets replaced at all] by the/an answer?
Or does mind set up any data node that tells "lack of information"? And the question gets generated instantly? -- And if so, does that generation take place when there's indeed a chance to get the question answered? But what might be the trigger for finding out that there's a chance to get the question answered?
Benefits of detecting and replacing kind N networks: revealing implied content
Added documentation to the sub-framework of detection of replacable partitial networks, and rewrote parts of initialization for a few classes. Actually, what I am talking here about is the kind N networks detection.
 Kind N networks, in the MOM terminology, are such ones of four or more nodes, two predecessors (cf. image: nodes A and B), two successors (nodes C and D), and each of the predecessors connected to each of the successors. That looks like a mixture of an "N" and an "X" character.
Kind N networks, in the MOM terminology, are such ones of four or more nodes, two predecessors (cf. image: nodes A and B), two successors (nodes C and D), and each of the predecessors connected to each of the successors. That looks like a mixture of an "N" and an "X" character.
As the X often gets used to indicate something unknown, but here is not anything unknown, that kind of network got called the N network. -- Add a pair of successor and predecessor, and it still looks somewhat like that X-N mixture. As it features more but two base and two top points, we call it a pure kind N network: any MOM sub-network that consists of an equal number of predecessor and successor nodes (and wires all the predecessor to the successor nodes) is called a pure kind N network. Thus, the N network, of course, is also a pure kind N network.
-- Add a pair of successor and predecessor, and it still looks somewhat like that X-N mixture. As it features more but two base and two top points, we call it a pure kind N network: any MOM sub-network that consists of an equal number of predecessor and successor nodes (and wires all the predecessor to the successor nodes) is called a pure kind N network. Thus, the N network, of course, is also a pure kind N network.
Then, there are chances, a network features more successor nodes but predecessor ones. If the number of predecessor nodes is >= 2, that kind of net gets called a kind W network, because of its shape. -- It gets called the W network, if it sports only two predecessor and exactly three successor nodes.
If the number of predecessor nodes is >= 2, that kind of net gets called a kind W network, because of its shape. -- It gets called the W network, if it sports only two predecessor and exactly three successor nodes. 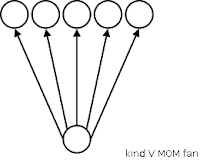 If a graph features only a single predecessor node, it's a kind V fan. Similar to the naming scheme for the W network, a kind V fan gets called the V fan, if its shape matches the letter: If it features a single predecessor and exactly two successor nodes.
If a graph features only a single predecessor node, it's a kind V fan. Similar to the naming scheme for the W network, a kind V fan gets called the V fan, if its shape matches the letter: If it features a single predecessor and exactly two successor nodes.
Put upside down, we get a kind M network, the M network, a kind A fan and the A fan, resepectively.
Because kind W/M networks follow the pure kind N network approach by wiring each predecessor with each successor node, all together -- kind W, kind M and pure kind N networks get summarized under the generic "kind N network" label.
So, the efforts done were to detect any kind N networks within a larger MOM network. Why? -- The complete wiring of each predecessor node with each successor node results in a situation,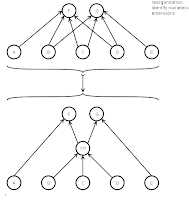 that the content of each successor node equals the content of all predecessor nodes together (plus the content of any separate predecessor nodes the successors don't share with their neighbours of that kind N network). The image aside shows it: Nodes F and G share the content of B, C and D. A becomes part of F only, so does E for G. -- That sharing of common predecessor nodes implies two things:
that the content of each successor node equals the content of all predecessor nodes together (plus the content of any separate predecessor nodes the successors don't share with their neighbours of that kind N network). The image aside shows it: Nodes F and G share the content of B, C and D. A becomes part of F only, so does E for G. -- That sharing of common predecessor nodes implies two things:
Now, part of it was rewritten and all of it documented. Now that sub-framework for kind N net detection needs to get spread into separate class files and put into a sub-directory or sub-directory hierarchy.
Updates: none so far
 Kind N networks, in the MOM terminology, are such ones of four or more nodes, two predecessors (cf. image: nodes A and B), two successors (nodes C and D), and each of the predecessors connected to each of the successors. That looks like a mixture of an "N" and an "X" character.
Kind N networks, in the MOM terminology, are such ones of four or more nodes, two predecessors (cf. image: nodes A and B), two successors (nodes C and D), and each of the predecessors connected to each of the successors. That looks like a mixture of an "N" and an "X" character.As the X often gets used to indicate something unknown, but here is not anything unknown, that kind of network got called the N network.
 -- Add a pair of successor and predecessor, and it still looks somewhat like that X-N mixture. As it features more but two base and two top points, we call it a pure kind N network: any MOM sub-network that consists of an equal number of predecessor and successor nodes (and wires all the predecessor to the successor nodes) is called a pure kind N network. Thus, the N network, of course, is also a pure kind N network.
-- Add a pair of successor and predecessor, and it still looks somewhat like that X-N mixture. As it features more but two base and two top points, we call it a pure kind N network: any MOM sub-network that consists of an equal number of predecessor and successor nodes (and wires all the predecessor to the successor nodes) is called a pure kind N network. Thus, the N network, of course, is also a pure kind N network.Then, there are chances, a network features more successor nodes but predecessor ones.
 If the number of predecessor nodes is >= 2, that kind of net gets called a kind W network, because of its shape. -- It gets called the W network, if it sports only two predecessor and exactly three successor nodes.
If the number of predecessor nodes is >= 2, that kind of net gets called a kind W network, because of its shape. -- It gets called the W network, if it sports only two predecessor and exactly three successor nodes.  If a graph features only a single predecessor node, it's a kind V fan. Similar to the naming scheme for the W network, a kind V fan gets called the V fan, if its shape matches the letter: If it features a single predecessor and exactly two successor nodes.
If a graph features only a single predecessor node, it's a kind V fan. Similar to the naming scheme for the W network, a kind V fan gets called the V fan, if its shape matches the letter: If it features a single predecessor and exactly two successor nodes.Put upside down, we get a kind M network, the M network, a kind A fan and the A fan, resepectively.
Because kind W/M networks follow the pure kind N network approach by wiring each predecessor with each successor node, all together -- kind W, kind M and pure kind N networks get summarized under the generic "kind N network" label.
So, the efforts done were to detect any kind N networks within a larger MOM network. Why? -- The complete wiring of each predecessor node with each successor node results in a situation,
 that the content of each successor node equals the content of all predecessor nodes together (plus the content of any separate predecessor nodes the successors don't share with their neighbours of that kind N network). The image aside shows it: Nodes F and G share the content of B, C and D. A becomes part of F only, so does E for G. -- That sharing of common predecessor nodes implies two things:
that the content of each successor node equals the content of all predecessor nodes together (plus the content of any separate predecessor nodes the successors don't share with their neighbours of that kind N network). The image aside shows it: Nodes F and G share the content of B, C and D. A becomes part of F only, so does E for G. -- That sharing of common predecessor nodes implies two things: - First, as any MOM node represents the merged content of its predecessor nodes, we could replace the heavy wiring by adding a new node and wire link all predecessor nodes of the kind N network to that newly added node and it to all the successor nodes. That way the number of edges needed to administer could get reduced from a * b to only a + b.
- Second, as now it might be obvious, that wiring of all the predecessor nodes to each of the successor nodes was nothing different but an implication. A not explied (?)/explicited (?) notion. By adding the node, we make it explicit.
Now, part of it was rewritten and all of it documented. Now that sub-framework for kind N net detection needs to get spread into separate class files and put into a sub-directory or sub-directory hierarchy.
Updates: none so far
Subscribe to:
Posts (Atom)
