No news here since a long while. However, today, I read liw's bit on tag hierarchies for photos. I'd like to comment on some of his key points:
First of all, liw sees some of the key issues dealing with tags rather than notions: He mentions aliases and raises the questions whether there should be tags allowed that have more but one name. -- I'll ask another question: What about different tags sharing the same name? That's called homonymy. The other, "aliases", is synonymy.
Another thing he's asking for: What about translations for tags? -- Well, there is the issue that there are words in one language that don't have a true translation in another language. Little known, but clear is this pair in English and German: "to round out" -- "abrunden" ("to remove sharp edges"//"to round in"). Also, all the foreign-langisms any language has is a sign for that there's not yet any matching translation for a foreign word. Think "kindergarten" in English.
Second, given the translations would equal the original meaning, what else would they be but synonyms?
In my opinion, this cries for using notions rather than words.
About the synonyms, liw raises another question: What about descriptions for the tags? This could be particularly useful if you'd share tag hierarchies and one receiving person would not know a certain tag.
Let me point out some usability/convenience issue here: First, how can sharing user A know which of his tags they'd need to describe in order receiving user B will fully get what the particular tag is about? Second, why would user A want to describe any of the tags they already know? What'd be their benefit of that, their reason for doing so? And also, would the receiver actually make very much use of tags they are unfamiliar with? Then, would it be worthwhile to exercise all that effort to describe the tags?
Finally, descriptions are probably the worst source of content for machines: Content is stuck in sentences. Machines are illiterate, and for the foreseeable future this isn't going to change. The effort you put into describing tags by descriptions you unlikely will get out of there for machines to process and, thought a bit further, also not for humans to take advantage of, since machines cannot take advantage of that knowledge buried there in sentences, incomprehensible to them.
Therefore, I'd like to push a little further what liw already incorporated in his approach to tagging: implicity. liw's idea is to imply one tag into the other. (It's great to see liw is is-a/has-a agnostic in his sample tag hierarchies. -- Shift it to the notion level, and you get what I am proposing with the model of meaning (MOM) all the time.) Therefore, instead of burying precious content into machines-incomprehensible sentences, just extend the idea of tagging: show the context tags of the given tag a user might not know. The terms/tags being neighboured to it likely would give a close clue of what the tag in question is about.
I just mentioned liw's is-a/has-a agnosticity in his sample hierarchies. (I refer to his clear line of "has a" in "Europe - Finland - Helsinki" vs. is-a in "Location - Europe" in the same hierarchy.) There's one last thing I'd like to point out: Once you allow has-a relationships you'll like get a network rather than a clear hierarchy.
MOM -- my model of meaning -- might be a resource for addressing the issues liw points out. However, MOM currently is not under active development, and although I'd very much like to assist to implement that tags implicity system -- or MOM --, as I am currently occupied finding an employment, I won't be of very much help here. However, I'd be glad to see somebody implement it or parts of it. Also, I might be able to check in some of my own sources in several languages into github as a resource to draw from. -- wrs_]
Monday, October 12, 2009
Sunday, March 01, 2009
progessing...
...given the case you've got time and the right focus/objective, suddenly a knot opens and flow comes...
It's amazing, in what a short period I get done (rudimentary versions of) the major components of this project I had on my table for such a long time. This time it's the recognizer. I just implemented a primitive variant of it -- in, originally, less than twenty lines of code.
Operating on tags found in the Debian package descriptions database, it can help you to quickly determine the Debian package(s) that suit you best, just by entering a few tags making sense.
Here are some examples:

The program reads from a list of tags known to exist within the Debian package descriptions database. Five of those tags get picked, that's the first line of each output, presented like an array. The next few lines tell how many packages had how many of the picked tags. [The dotted line is minimalist debug output.] And finally, you get the list of results, i.e. packages that probably suit the user's needs best, i.e. share the most tags with the query. The last line is gimmick. It just tells the length of the results line in bytes.
To avoid to overwhelm the user by the amount of results, the amount of results provided is restricted to five.
Now, next question is where to get more collections like the Debian one, where you have items, and a few tags for each item. Are you aware of any? Could you give directions? Pointers? Hints? -- I'd be glad!
Updates: none so far
It's amazing, in what a short period I get done (rudimentary versions of) the major components of this project I had on my table for such a long time. This time it's the recognizer. I just implemented a primitive variant of it -- in, originally, less than twenty lines of code.
Operating on tags found in the Debian package descriptions database, it can help you to quickly determine the Debian package(s) that suit you best, just by entering a few tags making sense.
Here are some examples:

The program reads from a list of tags known to exist within the Debian package descriptions database. Five of those tags get picked, that's the first line of each output, presented like an array. The next few lines tell how many packages had how many of the picked tags. [The dotted line is minimalist debug output.] And finally, you get the list of results, i.e. packages that probably suit the user's needs best, i.e. share the most tags with the query. The last line is gimmick. It just tells the length of the results line in bytes.
To avoid to overwhelm the user by the amount of results, the amount of results provided is restricted to five.
Now, next question is where to get more collections like the Debian one, where you have items, and a few tags for each item. Are you aware of any? Could you give directions? Pointers? Hints? -- I'd be glad!
Updates: none so far
Tuesday, February 17, 2009
A hack makes reorganization work
Progressed further: One important step taken: reorganization, now, basically, works. That's the pre-requisite for introducing quality control to recognition.
Below, there are two renderings of basically the same net: One rendered before, the other after reorganization.
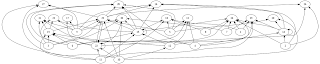

The net is broken because this reorg is a hack, and I therefore hacked together a generator too. (25) pointing to (22) and (15) pointing to itself can be seen as indicators for the brokenness of the generator.
However, what's important is that reorganization works.
Below, there are two renderings of basically the same net: One rendered before, the other after reorganization.


The net is broken because this reorg is a hack, and I therefore hacked together a generator too. (25) pointing to (22) and (15) pointing to itself can be seen as indicators for the brokenness of the generator.
However, what's important is that reorganization works.
Subscribe to:
Comments (Atom)
